

Health Insights: Nederlandse zorgkosten in beeld
Nieuws
Het gebruik van zorg en de kosten van zorg verschilt van gemeente tot gemeente, van wijk tot wijk en van buurt tot buurt. Deze verschillen zijn deels te verklaren doordat de samenstelling van de bevolking niet overal gelijk is. Maar ook na correctie voor de samenstelling van de bevolking blijven aanzienlijke verschillen zichtbaar. Juist deze overblijvende verschillen zijn interessant, omdat ze aanknopingspunten kunnen bieden om de doelmatigheid van de Nederlandse zorg te verbeteren.
Voor de analyse van het gebruik en kosten van de zorg maakt ahti gebruik van de CBS microdata. Deze data bevat van alle 17 miljoen Nederlanders demografische en sociaaleconomische kenmerken gecombineerd met gedetailleerde informatie over zorggebruik en kosten. Binnen de CBS omgeving kunnen hierdoor detailanalyses worden uitgevoerd. De resultaten daarvan worden zo samengevoegd dat ze anoniem zijn voordat ze buiten de CBS omgeving kunnen worden gebruikt. Zo wordt de privacy gewaarborgd.
Samen met haar partners geeft ahti betekenis aan de uitkomsten van de data-analyse: waarom zijn de verschillen zoals ze zijn? Is er een duidelijke sociale of medische reden? Zijn de uitkomsten van zorg in lijn met het gebruik en de kosten? Als er geen duidelijke reden is voor de waargenomen verschillen wordt met professionals gezocht naar interventies om de verschillen te verkleinen. Op deze manier gebruiken we publieke data om publieke vraagstellingen aan te pakken. Met als uiteindelijk doel de gerealiseerde waarde te vergroten.
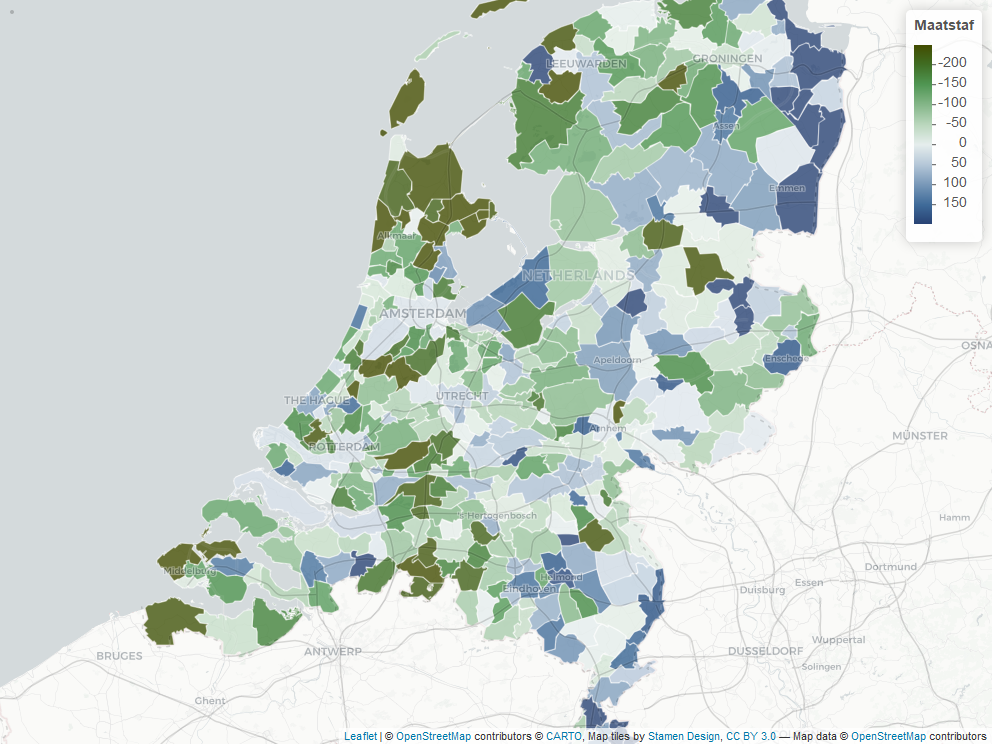
Verschil tussen werkelijke en verwachte per capita zorgverzekeringswet-kosten per gemeente (gecorrigeerd voor de samenstelling van de populatie, 2017 data)
Een voorbeeld van onze aanpak is te zien in bovenstaande kaart van Nederland en onderstaande kaart van Amsterdam. We hebben per gemeente, en ingezoomd op Amsterdam per buurt, per persoon weergegeven hoeveel de werkelijke kosten in de zorgverzekeringswet afwijken van de verwachte kosten. Hierbij is gecorrigeerd voor de samenstelling van de populatie in iedere gemeente/buurt.
Welke verklaringen zijn er voor deze verschillen? In ieder geval niet de samenstelling van bevolking op de kenmerken leeftijd, geslacht, inkomen, migratieachtergrond en huishoudsamenstelling, want daar is voor gecorrigeerd. Maar wat is het wel? Zijn er andere populatiekenmerken die een rol spelen? Is het gedreven door (een gebrek aan) aanbod? Zijn de kosten wellicht hoger (of lager), maar wel met betere (of slechtere) gezondheidsuitkomsten als resultaat? En als we de verschillen begrijpen: wat kunnen we er aan doen?
Zo zijn wij samen met zorgpartijen op zoek naar mogelijkheden om het Nederlandse zorgstelsel te verbeteren. Als jij wilt begrijpen hoe dat in jouw buurt, stad of regio is, dan duiken we daar graag samen in. Neem daarvoor contact op met Rachel van Beem, Head of Projects.
Verschil tussen werkelijke en verwachte per capita zorgverzekeringswet-kosten per buurt (gecorrigeerd voor de samenstelling van de populatie, 2017 data)